

570.133.20 and CUDA 12.8. You can scale from 1 to 8 GPUs per instance.
Prerequisites
- Phala Cloud account with sufficient credits
- Basic understanding of Jupyter notebooks
- Familiarity with command-line tools
Step 1: Deploy GPU TEE instance
Launch the deployment wizard
Sign in to cloud.phala.com, click GPU TEE in the navigation bar, then click Start Building to open the Launch GPU Instance wizard.Check your credit balance in the upper right corner. GPU instances incur hourly charges, so confirm your balance before launching.
Choose GPU hardware
Select your GPU type based on your compute needs.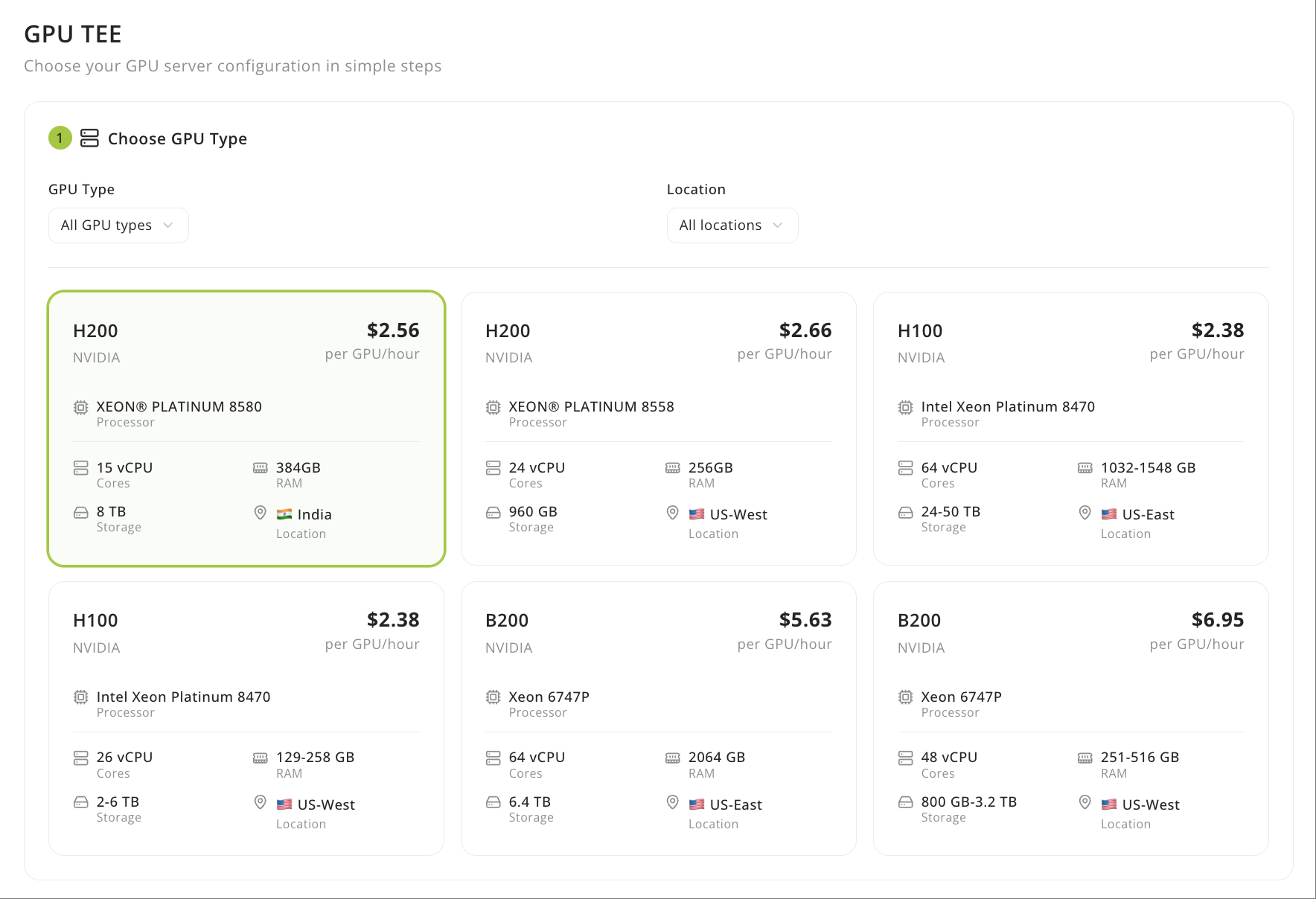
| GPU type | Region | vCPU cores | VRAM | RAM | Storage | Price* |
|---|---|---|---|---|---|---|
| H200 | US | 24 | 141 GB | 256 GB | 200 GB | $2.56/GPU/hour |
| H200 | India | 15 | 141 GB | 384 GB | 200 GB | $2.30/GPU/hour |
| B200 | US | 12 | 180 GB | 192 GB | 200 GB | $3.80/GPU/hour |
Configure GPU count
Choose the number of GPUs for your instance. You can scale from 1 to 8 GPUs per instance. The UI updates resource totals dynamically:| GPU count | Example: B200 | Total vCPU | Total VRAM | Total RAM | Total storage |
|---|---|---|---|---|---|
| 1 GPU | Single | 12 cores | 180 GB | 192 GB | 200 GB |
| 8 GPUs | Multi | 96 cores | 1 TB | 1 TB | 1 TB |
Configure deployment
Give your deployment a name or use the auto-generated name likegpu-tee-1p1qp. For the template, choose Jupyter Notebook (PyTorch) to get a GPU-accelerated JupyterLab environment with PyTorch and CUDA pre-installed. This template works well for running verification scripts and custom experiments.
You can also choose vLLM for an inference server or Custom Configuration to provide your own Docker Compose file. For this tutorial, we’ll use Jupyter Notebook because it gives us terminal access to run verification commands.
Select pricing plan
Choose a commitment period:| Plan | Rate | Notes |
|---|---|---|
| 6-month commitment | ~$2.88/GPU/hour | Includes storage, saves ~18% vs on-demand |
| 1-month commitment | ~$3.20/GPU/hour | Includes storage, short-term commitment |
| On-Demand | ~$3.50/GPU/hour + storage | Pay-as-you-go, no commitment |
Launch instance
Before launching, review the Instance Summary to confirm your GPU model and count, VRAM, RAM, and storage allocations, plus your total estimated costs.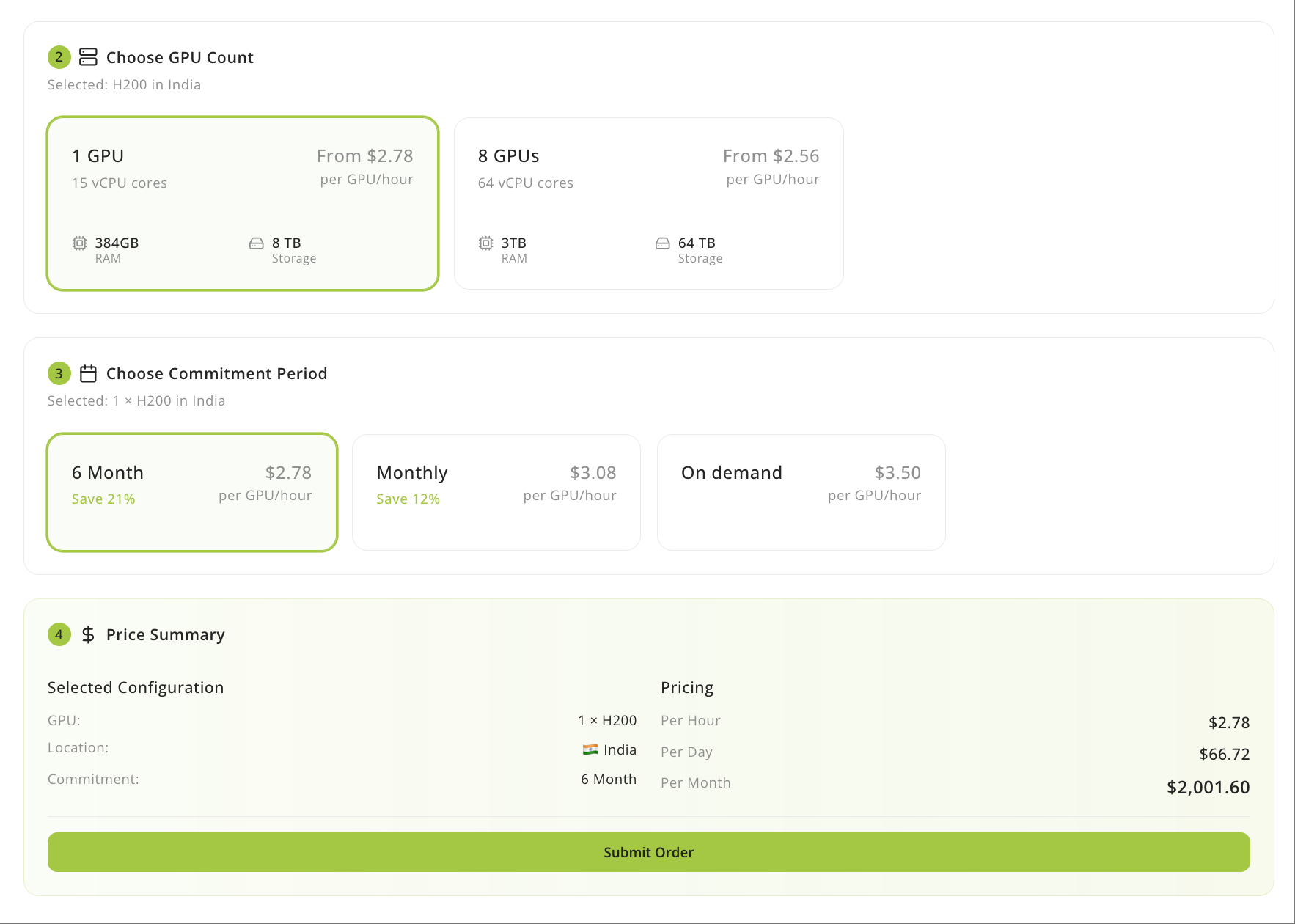
Step 2: Access your GPU TEE instance
After provisioning completes, your instance appears under the GPU TEE tab with connection details including the JupyterLab URL. Navigate to the GPU TEE tab in your dashboard and find your instance in the GPU Instances list. Click View Details to see the JupyterLab URL, then open that URL in your browser to access your instance.Monitor provisioning status in the GPU Instances list. Instances progress from Preparing → Starting → Running.
Step 3: Verify GPU TEE attestation
Open a terminal in JupyterLab (File → New → Terminal) to verify your instance runs on genuine TEE hardware.Check GPU and TEE status
First, confirm your GPU is detected and confidential compute mode is active. Runnvidia-smi to check GPU status:
CC State: ON and CPU CC Capabilities: INTEL TDX, confirming your instance runs in TEE mode.
Run attestation verification
Install NVIDIA’s attestation verification tools:Step 4: Confirm GPU functionality
Verify GPU functionality with PyTorch. Open a new notebook in JupyterLab (File → New → Notebook) and run:Next steps
You’ve deployed and verified a GPU TEE instance! Now you can:Programmatic verification
Learn how to fetch and verify attestations programmatically
Bind GPU and CPU attestations
Understand how GPU and CPU attestations create a complete trust chain
Expose services
Make your GPU TEE workloads accessible over HTTPS