> ## Documentation Index
> Fetch the complete documentation index at: https://docs.phala.com/llms.txt
> Use this file to discover all available pages before exploring further.
> Performance benchmarks and metrics for LLM inference in GPU TEE environments.
# Benchmark
## Key Results
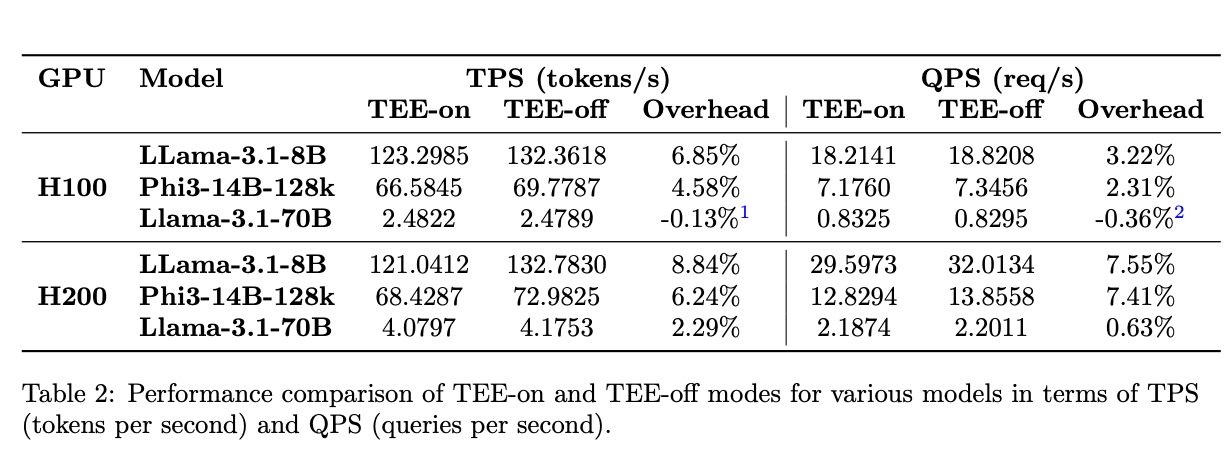
**TEE mode on H100/H200 GPUs runs up to 99% efficiency, nearly matching native performance.** This means you get confidential computing with minimal performance penalty.
The efficiency improves as your workload grows. Larger models and longer sequences see even better performance relative to native execution.
## What We Tested
We benchmarked LLM inference in GPU TEE mode using NVIDIA H100 and H200 GPUs. TEE mode encrypts your data and computation while it runs on the GPU.
 ## Performance Insights
* **Larger models perform better in TEE mode.** Models like Phi3-14B-128k and Llama3.1-70B show higher efficiency because they spend more time computing and less time on I/O operations.
* **Longer sequences boost efficiency.** When you process more tokens (input + output), the computation-to-I/O ratio improves. This makes TEE overhead less noticeable.
* **The sweet spot: High-computation workloads.** TEE mode shines when your GPU is doing heavy lifting. The encryption/decryption overhead becomes trivial compared to the actual computation time.
## Resources
For detailed metrics and analysis, check our [benchmark paper](https://arxiv.org/pdf/2409.03992).
See detailed [GPU TEE performance specifications](https://phala.com/gpu-tee) for production deployments, including [H100 TEE](https://phala.com/gpu-tee/h100) and [H200 TEE](https://phala.com/gpu-tee/h200) configurations.
## Performance Insights
* **Larger models perform better in TEE mode.** Models like Phi3-14B-128k and Llama3.1-70B show higher efficiency because they spend more time computing and less time on I/O operations.
* **Longer sequences boost efficiency.** When you process more tokens (input + output), the computation-to-I/O ratio improves. This makes TEE overhead less noticeable.
* **The sweet spot: High-computation workloads.** TEE mode shines when your GPU is doing heavy lifting. The encryption/decryption overhead becomes trivial compared to the actual computation time.
## Resources
For detailed metrics and analysis, check our [benchmark paper](https://arxiv.org/pdf/2409.03992).
See detailed [GPU TEE performance specifications](https://phala.com/gpu-tee) for production deployments, including [H100 TEE](https://phala.com/gpu-tee/h100) and [H200 TEE](https://phala.com/gpu-tee/h200) configurations.